Introduction to Data Cleansing
LILT uses a number of methods acquiring and processing parallel corpora with machine translation (MT). Some of the methods for cleansing include sentence alignment, filtering of noisy parallel corpora data, and monolingual pre-training. These high-level methods are broken down into steps outlined in the following section. Once data is cleaned, Data Sources can be uploaded for training.Data Cleanup and Quality Assurance Steps
The data cleanup process contains multiple steps that can be performed for data being imported to LILT Translate.Clean and validate
We perform a basic syntax-based cleaning using the below substeps:- Remove any blank sentences
- Remove sentences containing only punctuation
- Validate that source and target language files contain a matching number of segments (otherwise, discard the source).
Normalize Segments
To ensure consistency of all segments, the following steps can be performed:-
Normalize Unicode: Text like unicode or HTML text can be converted to human readable text. Eg Broken text\… it\’s flubberific! is converted to Broken text… it’s flubberific!
- A common method for normalizing unicode or HTML text is to use Python string and HTML parsing libraries.
- Normalize non-breaking spaces: For languages like French, where there are strict rules about positions of non-breaking spaces, this step adds the spaces where necessary, if they are not already present.
Filter
First, remove potentially problematic segments from a corpus at segment- or segment-pair-level. This is known as individual filtering.- Script: It’s a fair assumption that if a ja (Japanese) segment contains a ta (Tamil) token/phrase, it may not be usable during training. We maintain rules for scripts that are not effective when embedded in another script, and remove those segments.
- Language code: We use the python cld3 package to identify a segment’s language; if it doesn’t match the corpus language, it is discarded.
- Exclude patterns: We exclude segments matching regexes that identify problematic patterns, for example, “http://” for URLs
- Segment length: We exclude any segment longer than 300 words (configurable per language).
- Number mismatches: We exclude any segment pair which uses the same numeral system, but contains different numbers in the source and target segments.
- Length Ratio: We exclude any segments where the source or the target segments are unusually long or short for a segment pair, after comparing with a threshold computed on the entire corpus.
- Edit Distance: We exclude any segments where the source and target segments are identical or similar, since this may indicate mistranslation. We check the edit distance between the source and target segments against a minimum of 0.2.
Augment Data
When presented with unfamiliar or underrepresented data, machine translation models can fail by producing “hallucinations” — translated text that is divorced from the original source text. To ameliorate this problem, we artificially generate (augment) examples of parallel sentences. Training with the augmented examples improves the model’s robustness and resilience towards these data, allowing us to effectively translate a wide variety of customer domains. We augment existing segment pairs in the following ways:- Multi-segment: We concatenate up to 5 consecutive segments to form a single long segment.
- Capitalization: We capitalize the selected segments based on UPPERCASE and Title Case capitalization schemes.
- Non-Translatables: We introduce non-translatables used by our customers by detecting common tokens/phrases in source and target segments and wrapping them with ${ and } characters.
Byte-pair Encode (BPE)
The vocabulary for a large corpus can be huge, with many words seen rarely. We perform byte- pair encoding (BPE) on the words to break them down into word pieces (e.g., eating might be separated into eat and ing). This allows us to fix the size of the vocabulary, and in extension, the MT model and hence the resources required to train the model. BPE further allows us to translate segments with tokens which haven’t appeared in the training corpora, common in morphologically rich languages such as romance and slavic languages, since we can split tokens into familiar word pieces.Uploading New Data Sources for Training
This section walks through uploading memory files to new or existing Data Sources. Uploading memory files to a Data Source allows LILT to better find translation matches and provide translation suggestions within LILT Translate. All the LILT Data Sources you are the owner of are located under theData Sources button on the Data navigation.
Create new data source button in the upper-right. See Managing Data Sources for more details.
Edit data source button to open up the Data Source view.
Manage resources page. This page displays all documents that have been uploaded to the Data Source.
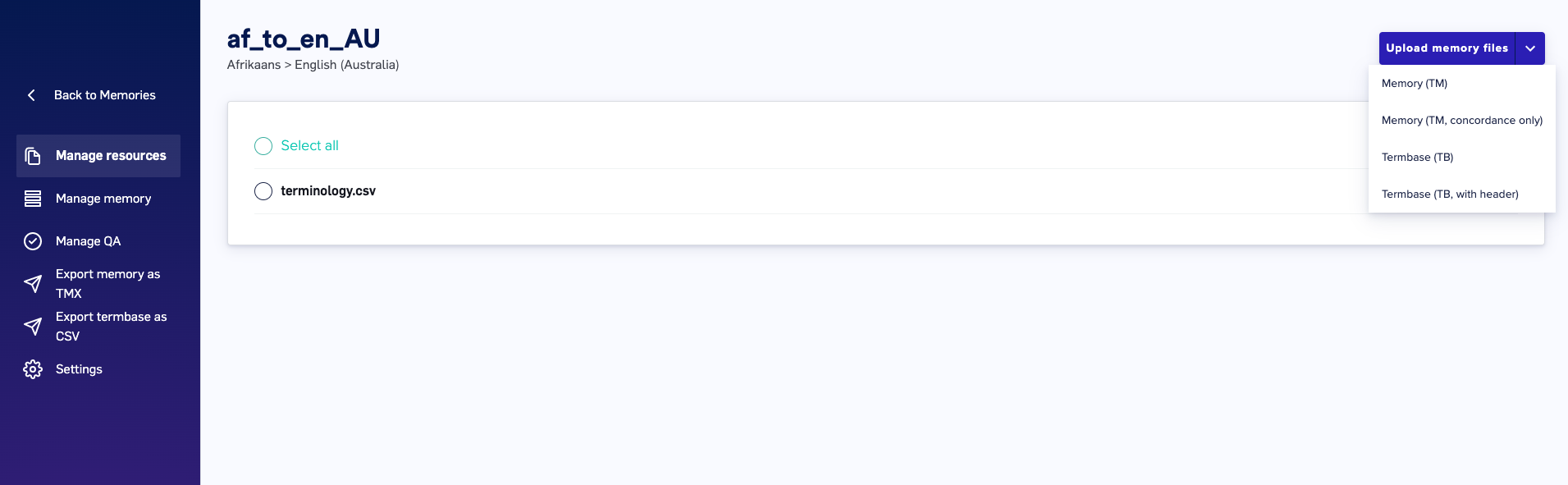
Upload memory files button in the upper-right and select the type of memory files you want to upload. Selecting one of the dropdown options will bring up a window for you to locate and select the files you want to upload. After the selected files are loaded into LILT, they will be available to view on the Manage resources page.
- Memory files can contain as many terms as you like, so long as the file adheres to the TM Size limits. In particular, individual files cannot exceed 200 MB. If files exceed this size, zip them before uploading. Once uploaded, the file will be parsed into individual, editable entries.
- See the Memory Maintenance Best Practices article for information on how to structure CSV files for uploading Termbases.
- Termbase column entries cannot contain more than 10,000 characters. When uploading a file where any column entries are more than 10,000 characters, LILT will not process the file and will display the following warning:
-
When importing JSON files as TM entries into LILT, use the format shown below to ensure your memory entries are properly imported:
- Memory (TM): Choose this option if you want your memory files to be indexed for Concordance, used to train the MT, and used as TM results. The MT model learns from uploaded data immediately upon upload. Note that deleting documents from a Data Source does not affect the MT model (i.e. the MT model does not unlearn the deleted resources). However, there is a recency bias, meaning the most recent documents have a stronger input on the translation output.
- Memory (TM, concordance only): Choose this option if you want your memory files to only be indexed for Concordance but not used to train the MT and not used as TM results.
- Termbase (TB): Choose this option if your Termbase document does not have a header and you want all entries to be added to the Termbase entries of the Data Source.
- Termbase (TB, with header): Choose this option if your Termbase document has a header at the top of the file that you want to exclude from adding to the Termbase entries of the Data Source.
Deleting Memory files
Click theDelete button in the upper-right to bring up a popup to confirm you want to permanently delete the selected resources. Deleting a resource permanently removes all that resource’s TM/TB entries from the Data Source.