Where TM matching is used in LILT
- TM segment suggestions: When working in LILT Translate, translation suggestions are provided to linguists for the active segment. If there are any TM matches above 75%, the best match will be displayed as the suggestion. However, if there are no such TM matches, LILT uses the associated Contextual AI model to provide suggestions to the linguist. Note that if the language pair does not have Contextual AI, no Contextual AI suggestions will be shown.
- Pretranslation: When Pretranslation is run, any segments that have 100% or 101% matches with TM entries in the associated Data Source are translated.
- TM Leveraging: LILT automatically leverages TM entries in the associated Data Source to populate the target text of empty, unreviewed segments with 100% or 101% matches. This is performed across all documents that share the Data Source.
- Overwrite Confirmed Segments: When a linguist confirms or accepts a segment in LILT Translate, Overwrite Confirmed Segments updates matching segments (100% and 101%) with the same changes.
TM match ordering
LILT leverages TM matches in the following order:
Note that the reviewed/unreviewed status of a TM entry does not affect match prioritization.
Prioritize recency setting
If enabled in Organization settings, this will disable 101% match priority and allow for recency-based match prioritization. 101% matches will be treated as equivalent to 100% matches, prioritizing recency over context precision.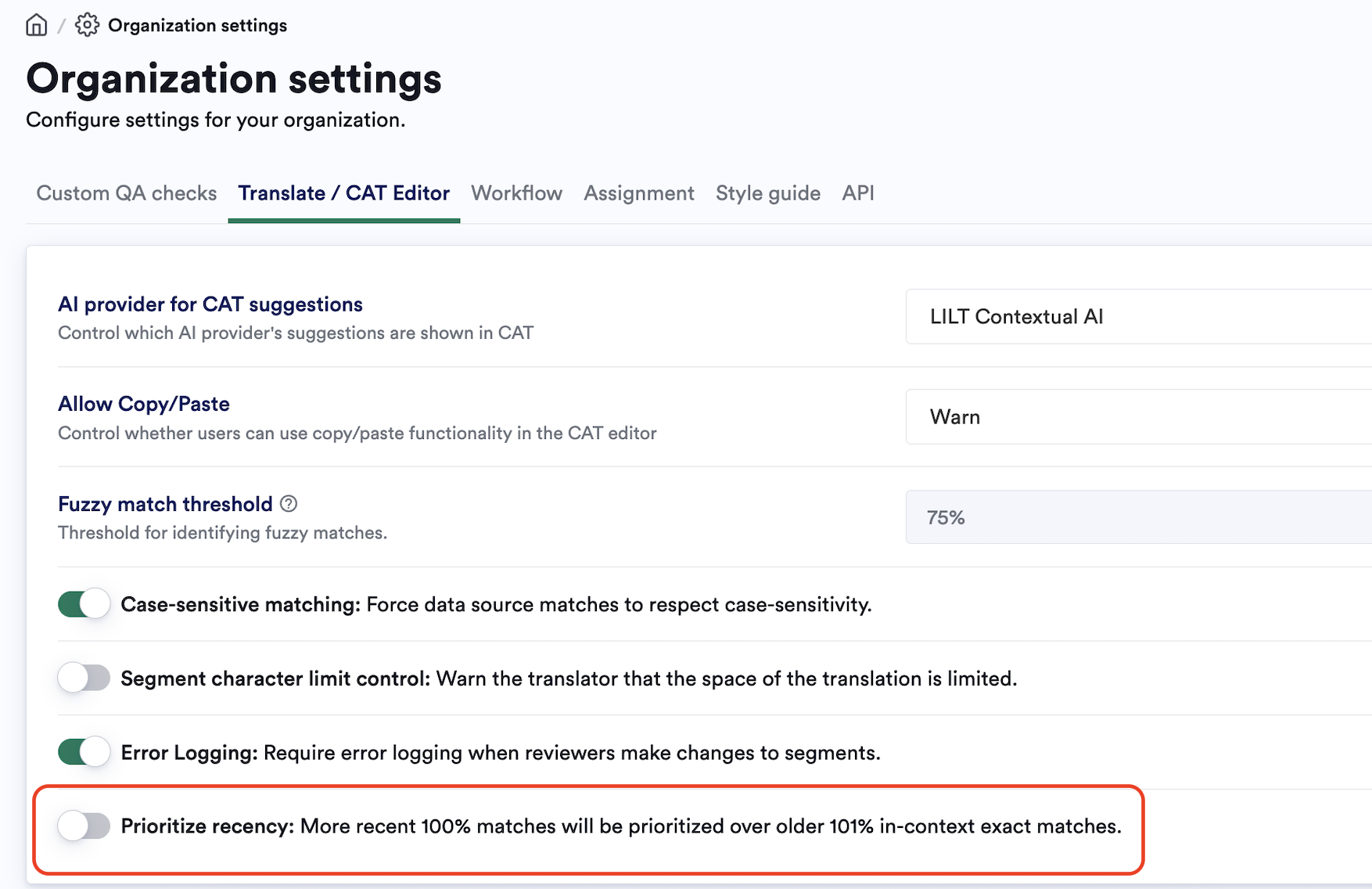
Prioritize recency setting
TM match scores
The table below outlines the various match scores in LILT.
The lowest match percentage available is 75%. This is a set threshold and not configurable.
If the Organization Setting for
Case-sensitive matching is enabled, TM match scoring takes into account any differences in letter casing; otherwise, casing is ignored.
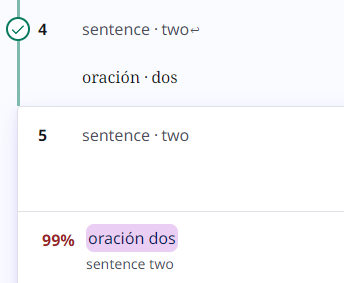
In LILT, 100% matches that have whitespace differences or tag differences are downgraded to 99% matches. In the example below, the bottom segment doesn’t have a new line whitespace like the top segment does, so the TM match for the bottom segment is displayed as a 99% match.
How TM match percentages are calculated
LILT uses an Edit Distance algorithm to calculate match percentages. However, because TMs can be large, it is not practical to compare every source segment to every entry in the TM. To simplify this problem, LILT first uses a Locality-Sensitive Hashing algorithm to find a subset of the TM that is roughly similar to the source string, and then calculates the match percentage against each of those possibilities. This process is not 100% guaranteed to always produce every possible fuzzy match candidate, but rather allows for an optimized balance between quality of TM matches with speed/time to match. In cases where our algorithm misses a fuzzy match, this is likely due to having multiple languages present in the same segment.TM suggestions in LILT Translate
Translation Memories (TM) entries are used to provide translation suggestions to linguists working in LILT Translate. When a segment is active in LILT Translate, the associated Translation Memory is checked for TM entries with similar phrases. If any TM entries are found with similar phrases to the segment, the highest matching, most recent TM entry is displayed under the segment as a translation suggestion.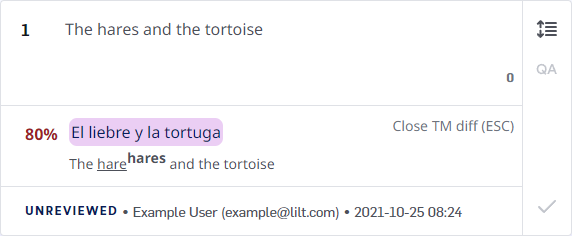
- 100% and 101% matches are automatically populated into the target text area (via TM Leveraging), rather than being provided as suggestions.
- If no matches exist above 75%, LILT provides a Contextual AI suggestion for the target text. If the language pair does not have MT support, no MT suggestion will be shown.
TM difference display
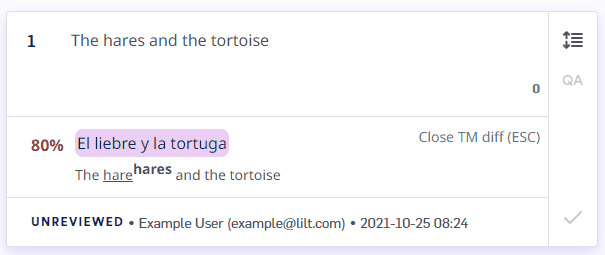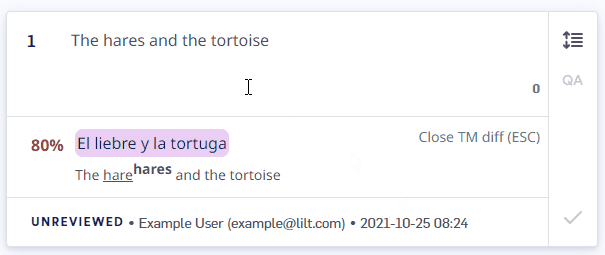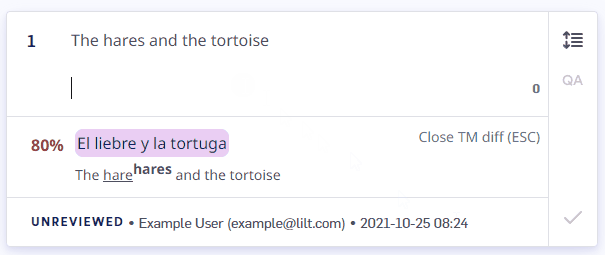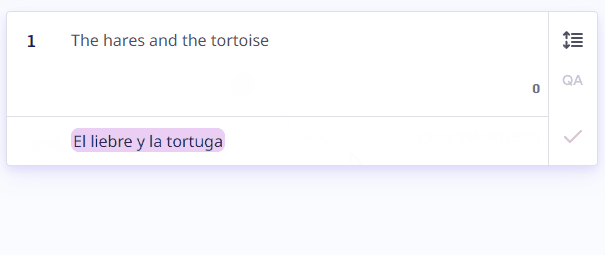
Fuzzy matches (less than 100%) are shown along with a display of the differences between the TM entry and the source. Let’s look at an example:-
Segment source text:
The hares and the tortoise -
TM entry:
The hare and the tortoise>La liebre y la tortuga
The hare<sup>hares</sup> and the tortoise. The TM entry uses hare, while the source uses hares. Any words in the TM suggestion that are missing from the source are underlined. Substitutions from the source are displayed in superscript.
Escape to close it. Once closed, you can still access and use the TM suggestion, but the TM diff display (including match percent) will go away. The diff display can be brought back by refreshing the page.
View all TM matches for a segment
If there are multiple suggestions, they can be viewed in the Segment Context pane on the right side of LILT Translate. TheSegment context pane displays TM matches sorted in the following order:
- Reviewed/unreviewed
- Match percent
- Most recently updated
Segment context pane is not the same as the TM match order. While the Segment context pane sorts by reviewed/unreviewed status, TM matching ignores reviewed/unreviewed status.
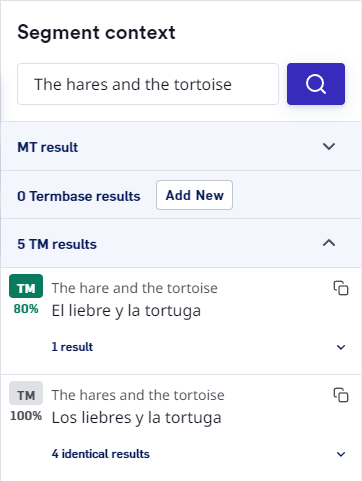
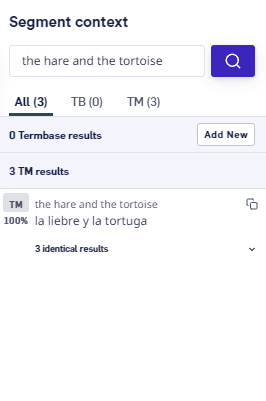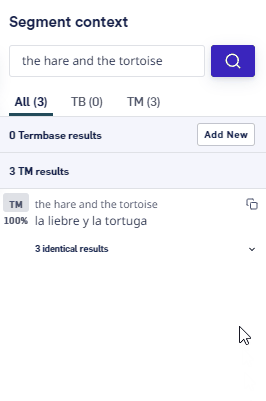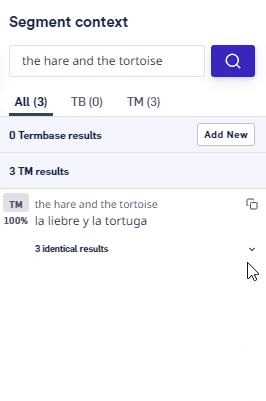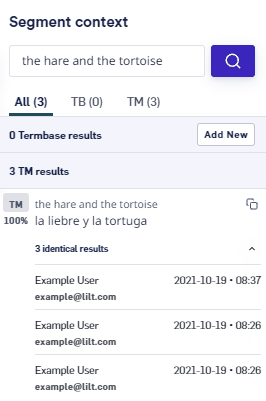
Segment context pane will display so. Click the identical results dropdown to display the following metadata for each identical TM entry:
- attributed user
- timestamp of when the entry was last updated
How TM entries are added to and removed from Data Sources
TM entry metadata: When a TM entry is added or modified, its metadata is updated:- Entry author: Email address of the author. Authorship is not always changed when an entry is updated. The sections below describe how and when authorship is updated.
- Entry timestamp: Date and time the TM entry was last updated. The time is displayed in the viewer’s time zone.
Linguist actions that update TM entries
The last person to confirm a segment is attributed as the TM entry author.
- When a reviewer accepts a confirmed segment without modifying the target text, the author is left as the translator who confirmed the segment.
- When a reviewer accepts an unconfirmed segment, they are given authorship.
- Reviews have the ability to unconfirm segments, meaning that if a reviewer unconfirms a segment and then accepts the segment, they will be given authorship.
Project manager actions that update TM entries
TM entries uploaded to the Data Source by a project manager are attributed to the TM entry authors listed in the TM file.
When a project manager manually adds a TM entry on the
Manage entries page, they are made the author of the entry.
When a project manager manually modifies a TM entry on the Manage entries page, authorship is not changed.
Automated processes that update TM entries
TM Leveraging and Overwrite Confirmed Segments attribute authorship to the user in the document when TM Leveraging or Overwrite Confirmed Segments is run.
Pretranslation attributes authorship to either the project manager or the author of the matching entries (depending on the Pretranslation settings).